
Machine learning is a subcategory of artificial intelligence.
Machine learning applies statistical techniques to learn from a set of examples. It is all about learning from example.
The most common form of machine learning is supervised machine learning. Supervised learning is the machine learning task of inferring a function from labeled training data.
The training data consists of a set of training example that need to be understood really well. The data also needs to be of high quality.
The accuracy of the results is then confirmed by validating the machine learning system with previously unseen data whose results are also well under stood. It is critical to understand the accuracy of a machine learning system in order appreciate the quality of the results produced when presented with previously unseen data.
In machine learning we provide features (or input) of a data set to an algorithm in order to identify labels (output).
For example:
Let say we wanted to apply machine learning algorithm to categorise animals. The features may be such things as the number of legs, if the animal has a tail, or if the animal has antlers. The labels that we desire as output could be the categorisation of the species such as Mammal, Bird, Reptile, Fish, Amphibian, Bug or an Invertebrate.
Through the application of a machine learning algorithm we try to define what is called a decisions surface. A decision surface is the boundary between labels given a set of features.
For example: Linear Decision Surface
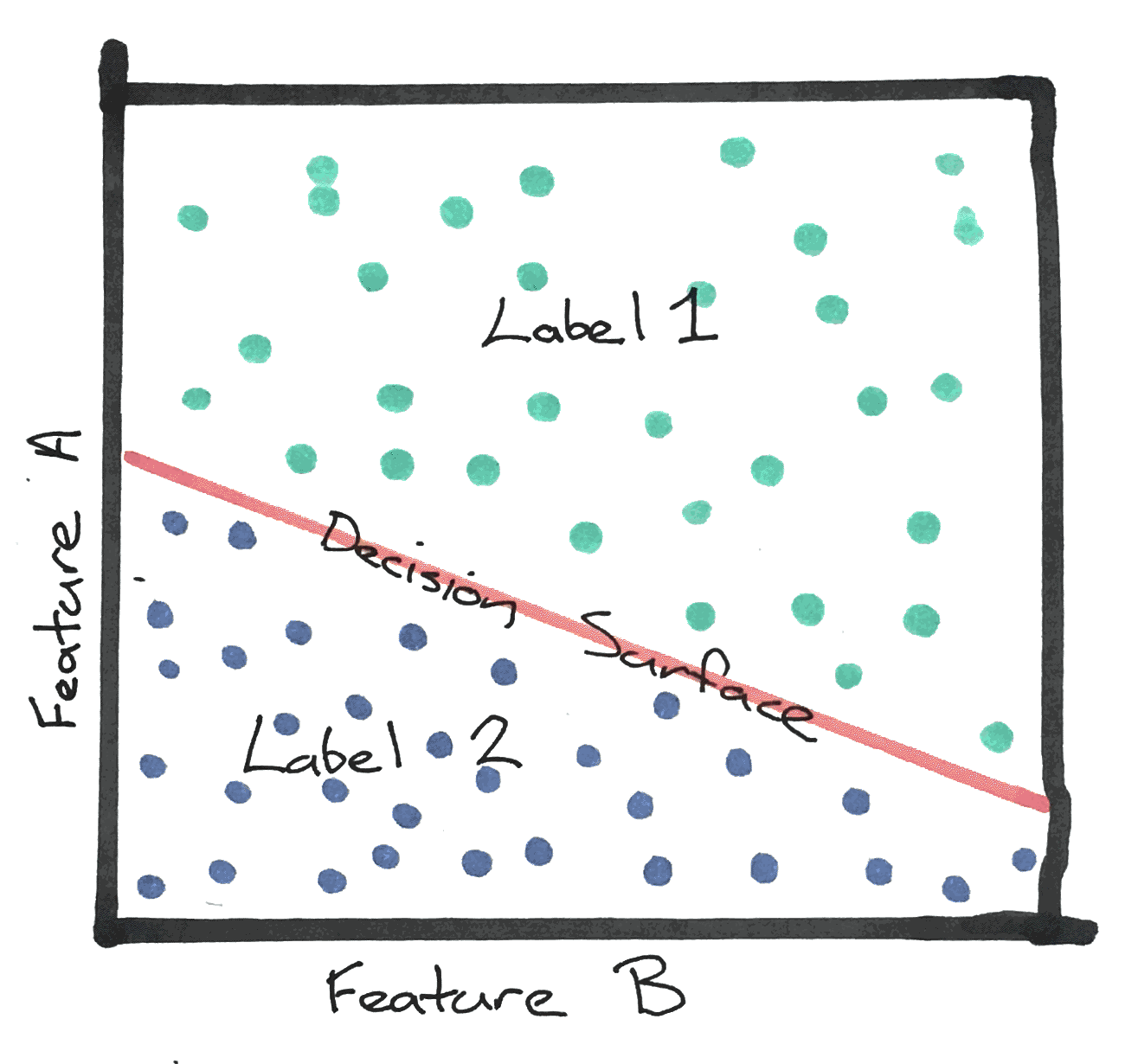
For a previously unseen piece of data where “feature A” and “feature B” are applicable, we should be able to categorise it into either “label 1″ or label 2” with a high degree of certainty based on the identified decision surface if the accuracy of the machine learning algorithm is sufficiently high and has been based on a large enough training data set.
So in summary, a machine learning algorithm takes a known set of data and transforms it to produce a decision surface so that all future cases can be classified.